tl;dr
I ordered a carbon monoxide detector from a 3rd party Amazon seller and they sent me one that’s way past its expiration date. I tried to write a negative seller review, and found myself
sucked in the Kafkaesque world of Amazon Support. In the end, I never was able to get my review posted, despite trying pretty much everything.
I don’t know if this is particularly interesting to others, but in any case, this is the story…
The perfect seller
October 5th: My carbon monoxide detector had reached the end of its life, so I did what I always do: I went to Amazon and looked for a replacement. I quickly settled on this model which has good reviews.
Where it gets interesting is when I found I could save a tiny bit by going with a 3rd party seller instead of Amazon. The difference was under a dollar, but it was just as simple, so my cheapness sense took over, and I went with that.
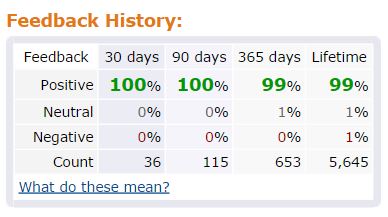
Of course, I checked the seller ratings: 100% positive over the past 3 months, and 99% lifetime. Surely, I had found the world’s most trustworthy seller: Great Lake Toys:
Dreams shattered
It arrived quickly (Go Prime!), and I proceeded to install it. As I was writing the date on it (always a good habit), I noticed a disturbing detail: it had been manufactured on July 19, 2007!

So wait, this detector is rated good for 5 years, but was made over 7 years ago? For a device that’s supposed to save my family in case of a CO leak, that’s not exactly what I want to see. Time to give them a one star review:
I ordered a Carbon Monoxide detector. When I opened it, I saw that the date of manufacture was July 2007, more than 7 years ago!! For a safety device that is supposed to last 5 years, that is a scary finding. I’m guessing that it’s been sitting in a garage for 7 years, and that it will not be performing well. And I’m not seeing an obvious way to contact the seller to get a fresher replacement :(
Rejection
October 13th: I get a response from Amazon that my review had been rejected, with message:
Feedback submitted was a product review and not related to seller
WTF?!
October 19th: I write back to Amazon
My review of this product was removed with the comment “Feedback submitted was a product review and not related to seller”.
This is not a correct resolution. I’m sure the product in general is fine. The problem is that the specific detector that the seller sent me was manufactured in July 2007, and is way too old to be used as a life safety device.
This is not a product review, but a case of the seller sending an item that is too old to be sold to customer. Hence it is absolutely a seller issue.
Also, there appears to be no way of contacting the seller.
I would appreciate if you could restore my review, and let me know what my options are.
October 20th: Amazon replies
I’ve forwarded the details you sent us to our investigations team. Each report they receive is investigated and the appropriate action is taken. However, we won’t be able to release the outcome of the investigation.
Anytime you buy from a seller, we encourage you to rate the seller’s performance through feedback. You have 90 days from the date of your order to leave a rating and comments on your experience. I’d suggest you to please resubmit your review.
Best regards,
Yogesh P
That was the first promise to send my case to the ‘investigation team’.
As for resubmitting my review, brilliant idea, except for one small detail: the button to submit a seller review is no longer there…
October 21st:
Hi Yogesh,
Thanks for your reply. I’m not finding a way to re-submit my feedback. I see the item under ‘order history’, but there is no ‘Leave Seller Feedback’ button.
Please advise how I can restore my feedback.
Thanks,
David
I then ‘pinged’ then twice more as I was not hearing back. I can be persistent :)
October 26th:
Hello,
I understand that you want to re submit the feedback with the seller.
I’m sorry; once feedback for a seller has been removed or posted, it can’t be restored or re-submitted as new feedback for that seller.
Best regards,
Swathi
Ok, now they’re starting to piss me off.
Hello,
I think there is a misunderstanding here. I did not remove the seller review. It was removed by Amazon, and it was done mistakenly as discussed. Can you please re-enable the ability for me to repost my review?
Thanks,
David
Same day, I hear back:
Hello,
I have forwarded this issue to our community review department, they receive is investigated and the appropriate action is taken. Your comments and suggestions will help us improve our store and offer better service to our customers.
They will write back to you after investigate the issue.
Best regards,
Shalu S
That was the second promise to have the review department take a look. Still, I’m a nice guy, so I show some appreciation for her fine work:
Thank you Shalu, your help is appreciated.
David
And within minutes, I hear back:
Hello,
Thanks for writing back with your kind words. I’m glad to hear that my colleague, Shalu, was able to assist you, and I’ll be sure to forward your message.
We look forward to seeing you again soon.
Best regards,
Inderjeet S
So now this guy is acting like all my issues have been resolved, and he’s super happy that his colleague was able to help me. That’s very nice.
Only problem is: I never hear back from them, nor from the now-infamous (and probably non-existing) ‘review department’.
November 6th
For the fun of it, I decide to post my original seller review as a product review. After all, the reason it got rejected in the first place was that they claimed it was a product review, so let’s play along!
Later that day, I get a reply:
Hello David,
I hope this email finds you well. This is Kath from the Communities team.
We encourage reviews on Amazon.com website, both positive and negative.
However, your recent review titled “Received expired carbon monoxide detector” for “First Alert CO600 Plug In Carbon Monoxide Alarm “ doesn’t comply with our customer reviews guidelines. Specifically, your review isn’t a review of the product itself, but rather a review of the seller from which you ordered.
Best regards,
Kath A.
You don’t say!
Just give me a new one
November 7th
I finally get around to returning the item, and ordering a new one from real Amazon (i.e. not a 3rd party seller). The returning part was smooth enough, and the new detector was as fresh as it gets.

It was manufactured on September 24th 2014, less then two months earlier! Very nice, and it confirms that how unacceptably stale the initial detector was.
Chat time
Now you might say that my problem is solved, as I’m in possession of a freshly minted detector. But part of me really wants to answer the question: is it at all possible to post a negative seller review?
So I decide to keep the fun going a bit. This time, I choose to go with a direct chat with customer service.
You are now connected to Ravi from Amazon.com
Me:I’m trying to write a Seller review for this order (107-3573704-4046606) but I’m not able to. Can you please help?
Ravi:Hello, my name is Ravi. I’ll certainly try to help regarding your concern.
Me:I wrote a review back on 10/19, but it was incorrectly removed with the comment “Feedback submitted was a product review and not related to seller”
Ravi:Hi, David.
I’m so sorry to hear this from you.
Let me help you.
Please provide the issue in detail.
Me:When I opened it, I saw that the date of manufacture was July 2007, more than 7 years ago. But the detector is only good for 5 years, so it is expired.
Ravi:I’m so sorry for the inconvenience.
Are you referring to this item?
First Alert CO600 Plug In Carbon Monoxide Alarm.
Me:Yes, that is correct. It’s a life safety device, so I don’t want to take chances with such an old item.
Ravi:Let me help you in this issue.
I’ll go ahead and request for the return label to return the item for full refund.
I suggest you to please return the expired item back to us for the full refund.
I can assure that this won’t happen again.
Me:I’ve already initiated the return today. But my issue here is that I’d like to leave a Seller review and I’m not able to.
Ravi:This item is fulfilled by Amazon. So we’ll will take care of this issue.
We’re the responsible for this inconvenience.
In addition to our large selection, one of the benefits we try very hard to offer our customers is convenience. I’m very sorry for the inconvenience you experienced in this case.
Me:On the seller’s page, I see reviews by other users who have bought from them, so it is possible to leave reviews for the specific seller. But right now I am not able to.
The problem is that my review was incorrectly removed saying it was a ‘product review’, which it wasn’t. It’s a seller review. But now the site won’t let me resubmit it
Ravi:I can understand your concern.
Me:This is the page with user reviews: link
Ravi:I’ll go ahead and forward this feedback to the investigation team.
Me:They have lots of new reviews everyday by users. I just want to add mine. Note that I made that same request earlier and they also said they’d forward to investigation team. But I did not hear back. Is there a way you can check the status of previous investigation?
Ravi:Sure, David. I’ve forward this issue to our investigation team.
Me:Thanks Ravi. Will I hear back from them via email?
Ravi:The investigation team will take the appropriate steps and should hear within 1-2 business days.
Me:Ok, thanks Ravi for your help. I will be awaiting follow up from them.
Ravi:Sure.
You’re most welcome.
Is there anything else I can do for you today?
Me:No, thank you, that was it.
Ravi:You’re welcome! It’s certainly my pleasure assisting you. Thanks for contacting Amazon. We hope to see you again soon.
Have a good one! bye!
Ok, so that’s now the third promise to have the investigation team look it it!
November 16th
I haven’t heard anything back, so time for another chat with my Amazon friends!
You are now connected to Jeric from Amazon.com
Me:I had a chat with customer service (Ravi) relating this item on 11/7. He said an investigation was being launched and that they would get back to me within 1-2 business days, but I have not heard back. I’d like to check the status.
Jeric:Hello David , my name is Jeric. I’m sorry to know that you haven’t yet received the response.
No worries, I’ll be glad to check this for you and see what I can do to help.
Me:Thank you Jeric
Jeric:It’s my pleasure David.
I will need to gather additional information may I place you on hold for a couple of minutes?
Me:Yes, no problem.
Jeric:Thanks David, please hold on.
Please bear with me David.
Thank you for holding David.
Just to be sure you are referring to your feedback to the item you received expired, right David ?
Me:Yes, specifically the seller feedback that I have not been able to re-submit
I did initially but it had been mistakenly removed
Jeric:Thanks for verifying David. I checked the issue and I am sorry that you haven’t yet received the response. I’ll go ahead and forward this issue to our team.
Me:Were you able to find a record of the previous request for investigation?
Jeric:Yes David but I am not able to find the response yet. I’ll go ahead and resubmit your concern about the issue. I also suggest that you can write your review for the item.
Me:I cannot submit it right now, because the button to do this is gone.
That’s in fact the reason I had to contact service. If I was able to post the review, I would have just done it.
Jeric:Oh. I am so sorry to know that David.
Me:Please make it clear to the investigation team that this is now the 3rd time that a request is made to them. Each time I’m being told that I’ll hear back soon, and it never happened.
Jeric:David can you please try this link: link
Me:This link is for a product review. I want to post a seller review.
This is the seller link: link
Jeric:Thanks David.
Can you please try if this link will work: link
Me:this seems different from a seller review. A seller review is one that would end up showing up on the seller page for others to see. While this one appears to be a way to contact Amazon.
Jeric:Thanks so much David. I will also re-forward your issue to our team fro the investigations.Customer feedback like yours really helps us continue to improve our store and provide better service to our customers.Customer feedback like yours really helps us continue to improve our store and provide better service to our customers.
Me:Thank you. When should I expect to hear back?
Jeric:The team will responds once the investigations is done. According to my experience it takes 1-2 business days David.
Me:Ok, I will wait for this. Thanks for your help.
Jeric:You’re always welcome. It’s my pleasure to help you.
Did I cover all your concerns for today? If you have another issue I’ll be more than happy to assist you with this.
Me:That was the only issue, thanks.
Jeric:It’s my pleasure David.
Thanks for visiting Amazon.com and have a great day! Bye for now :)
So now for the fourth time, my case is sent to the hard working investigation team. And of course, I never hear back. This is the point where I decide that it isn’t much fun anymore, and I concede defeat against an insurmountable enemy.
Conclusions
If you’ve read this far, the first conclusion is that you have no life, and that you are thinking the same thing about me. That puts us on even ground.
The second conclusion is that Amazon Seller ratings are basically a scam. Positive reviews go in (if they’re even real), while legitimate negative reviews get rejected. Naturally, that leads to questionable sellers getting extremely high ratings.
I’ve been wondering what incentive Amazon has to protect 3rd party seller ratings so much. My guess is that there is some shady money deal between them that leads to that. It does seem strange that a company like Amazon would do this, but it’s not implausible.
But then again, as the saying goes “Never attribute to malice that which can be adequately explained by stupidity”. So it’s conceivable that it is a case of extreme incompetence. But that’s a lot less fun, so I’ll go with the conspiracy theory.
Time to go to sleep and breath in some deadly odorless gas.

































